SSC Journal Club: Cipriani On Antidepressants
I.
The big news in psychiatry this month is Cipriani et al’s Comparative efficacy and acceptability of 21 antidepressant drugs for the acute treatment of adults with major depressive disorder: a systematic review and network meta-analysis. It purports to be the last word in the “do antidepressants work?” question, and a first (or at least early) word in the under-asked “which antidepressants are best?” question.
This study is very big, very sophisticated, and must have taken a very impressive amount of work. It meta-analyzes virtually every RCT of antidepressants ever done – 522 in all – then throws every statistical trick in the book at them to try to glob together into a coherent account of how antidepressants work. It includes Andrea Cipriani, one of the most famous research psychiatrists in the world – and John Ioannidis, one of the most famous statisticians. It’s been covered in news sources around the world: my favorite headline is Newsweek’s unsubtle Antidepressants Do Work And Many More People Should Take Them, but honorable mention to Reuters’ Study Seeks To End Antidepressant Debate: The Drugs Do Work.
Based on the whole “we’ve definitely proven antidepressants work” vibe in coverage, you would think that they’d directly contradicted Irving Kirsch’s claim that antidepressants aren’t very effective. I’ve mentioned my disagreements with Kirsch before, but it would be nice to have a definitive refutation of his work. This study isn’t really it. Both Kirsch and Cipriani agree that antidepressants have statistical significance – they’re not literally doing nothing. The main debate was whether they were good enough to be worth it. Kirsch argues they aren’t, using a statistic called “effect size”. Cipriani uses a different statistic called “odds ratio” that is hard to immediately compare.
[EDIT: Commenters point out that once you convert Cipriani’s odds ratios to effect sizes, the two studies are pretty much the same – in fact, Cipriani’s estimates are (slightly) lower. That is, “the study proving antidepressants work” presents a worse picture of antidepressants than “the study proving antidepressants don’t work”. If I had realized this earlier, this would have been the lede for this article. This makes all the media coverage of this study completely insane and means we’re doing science based entirely on how people choose to sum up their results. Strongly recommend this Neuroskeptic article on the topic. This is very important and makes the rest of this article somewhat trivial in comparison.]
Kirsch made a big deal of trying to get all the evidence, not just the for-public-consumption pharma-approved data. Cipriani also made such an effort, but I’m not sure how comparable the two are. Kirsch focused on FDA trials of six drugs. Cipriani took every trial ever published – FDA, academia, industry, whatever- of twenty-one drugs. Kirsch focused on using the Freedom Of Information Act to obtain non-public data from various failed trials. Cipriani says he looked pretty hard for unpublished data, but he might not have gone so far as to harass government agencies. Did he manage to find as many covered-up studies as Kirsch did? Unclear.
How confident should we be in the conclusion? These are very good researchers and their methodology is unimpeachable. But a lot of the 522 studies they cite are, well, kind of crap. The researchers acknowledge this and have constructed some kind of incredibly sophisticated model that inputs the chance of bias in each study and weights everything and simulates all sorts of assumptions to make sure they don’t change the conclusions too much. But we are basically being given a giant edifice of suspected-crap fed through super-powered statistical machinery meant to be able to certify whether or not it’s safe.
Of particular concern, 78% of the studies they cite are sponsored by pharmaceutical industries. The researchers run this through their super-powered statistical machinery and determine that this made no difference – in fact, if you look in the supplement, the size of the effect was literally zero:
In our analyses, funding by industry was not associated with substantial differences in terms of response or dropout rates. However, non-industry funded trials were few and many trials did not report or disclose any funding.
This is surprising, since other papers (which the researchers dutifully cite) find that pharma-sponsored trials are about five times more likely to get positive results than non-sponsored ones (though see this comment). Cipriani’s excuse is that there weren’t enough non-industry trials to really get a good feel for the differences, and that a lot of the trials marked “non-industry” were probably secretly by industry anyway (more on this later). Fair enough, but if we can’t believe their “sponsorship makes zero difference to outcome” result, then the whole thing starts seeming kind of questionable.
I don’t want to come on too strong here. Science is never supposed to have to wait for some impossible perfectly-unbiased investigator. It’s supposed to accept that everyone will have an agenda, but strive through methodological rigor, transparency, and open debate to transcend those agendas and create studies everyone can believe. On the other hand, we’re really not very good at that yet, and nobody ever went broke overestimating the deceptiveness of pharmaceutical companies.
And there was one other kind of bias that did show up, hard. When a drug was new and exciting, it tended to do better in studies. When it was old and boring, it tended to do worse. You could argue this is a placebo effect on the patients, but I’m betting it’s a sign that people were able to bias the studies to fit their expected results (excited high-tech thing is better) in ways we’re otherwise not catching.
All of this will go double as we start looking at the next part, the ranking of different antidepressants.
II.
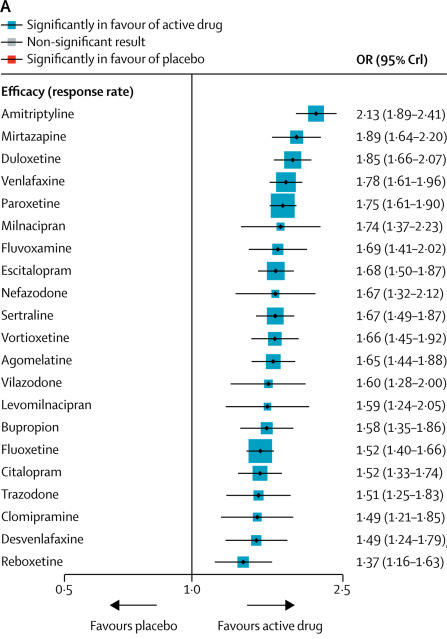 All antidepressants, from best to worst! (though note the wide error bars)
All antidepressants, from best to worst! (though note the wide error bars)
If this were for real, it would be an amazing resource. Psychiatrists have longed to know if any antidepressant is truly better than any other. Now that we know this, should we just start everyone on amitriptyline (or mirtazapine if we’re worried about tricyclic side effects) and throw out the others?
(as a first line, of course. In reality, we try the best one first, but keep going down the list until we find one that works for you and your unique genetic makeup.)
This matches some parts of the psychiatric conventional wisdom and overturns other parts. How much should we trust this versus all of the rest of the lore and heuristics and smaller studies that have accreted over the years?
Some relevant points:
1. The study finds that all the SSRIs cluster together as basically the same, as they should. The drugs that stand out as especially good or especially bad are generally unique ones with weird pharmacology that ought to be especially different. Amitriptyline is a tricyclic, and very different from clomipramine which is the only other tricyclic tested. Mirtazapine does weird things to presynaptic norepinephrine. Duloxetine and venlafaxine are SNRIs. This passes the most obvious sanity check.
2. Amitriptyline, the most effective antidepressant in this study, is widely agreed to be very good. See eg Amitriptyline: Still The Leading Antidepressant After 40 Years Of Randomized Controlled Trials. Amitriptyline does have many side effects that limit its use despite its impressive performance. I secretly still believe MAOIs, like phenelzine and tranylcypromine, to be even better than amitriptyline, but this study doesn’t include them so we can’t be sure.
3. Reboxetine, the least effective antidepressant in this study, is widely known to suck. It is not available in the United States becaues the FDA wouldn’t even approve it here.
4. On the other hand, agomelatine, another antidepressant widely known to suck, gains solid mid-tier status here, being about as good as anything else. The study even lists it as one of seven antidepressants that seems to do especially well (though it’s unclear what they mean and it’s obviously a different measure than this graph). But agomelatine was rejected by the FDA for not being good enough, scathingly rejected by the European regulators (although their decision was later reversed on appeal), and soundly mocked by various independent organizations and journals (1, 2). It doesn’t look like Cipriani has access to any better data than anyone else, so how come his results are so much more positive?
5. Venlafaxine and desvenlafaxine are basically the same drug, minus a bunch of BS from the pharma companies trying to convince that desvenlafaxine is a super-new-advanced version that you should spend twenty times as much money on. But venlafaxine is the fourth most efficacious drug in the analysis; desvenlafaxine is the second least efficacious drug. Why should this be? I have similar complaints about citalopram and escitalopram. Should we privilege common sense over empiricism and say Cipriani has done something wrong? Or should we privilege empiricism over common sense and conclude that the super-trivial differences between these chemicals have some outsized metabolic significance that makes a big clinical difference? Or should we just notice that the 95% confidence intervals of almost everything in the study (including these two) overlap, so really Cipriani isn’t claiming to know anything about anything and it’s not surprising if the data are wrong?
6. I’m sad to see clomipramine doing so badly here, since I generally find it helpful and have even evangelized it to my friends. I accept that it has serious side effects, but I expected it to do at least a little better in terms of efficacy.
Hoping to rescue its reputation, I started looking through some of the clomipramine studies cited. First was Andersen 1986, which compared clomipramine to Celexa and found some nice things about Celexa. This study doesn’t say a pharmaceutical company was involved in any way. But I notice the study was done in Denmark. And I also notice that Celexa is made by Lundbeck Pharmaceuticals, a Danish company. Am I accusing an entire European country of being in a conspiracy to promote Celexa? Would that be crazy?
The second clomipramine study listed is De Wilde 1982, which compared clomipramine to Luvox and found some nice things about Luvox. This study also doesn’t say a pharmaceutical company was involved in any way. But I notice the study was done in Belgium. And I also notice that Luvox is made by Solvay Pharmaceuticals, a Belgian company. Again, I’m sure Belgium is a lovely country full of many people who are not pharma shills, but this is starting to get a little suspicious.
To Cipriani’s credit, his team did notice these sorts of things and mark these trials as having “unclear” sponsorship levels, which got fed into the analysis. But I’m actually a little concerned about the exact way he did this. If a pharma company sponsored a trial, he called the pharma company’s drug’s results biased, and the comparison drugs unbiased. That is, suppose that Lundbeck sponsors a study, comparing their new drug Celexa to old drug clomipramine. We assume that they’re trying to make it look like Celexa is better. In this study, Cipriani would mark the Celexa patients as biased, but the clomipramine patients as unbiased.
But surely if Lundbeck wants to make Celexa look good, they can either finagle the Celexa numbers upward, finagle the clomipramine numbers downward, or both. If you flag Celexa as high risk of being finagled upwards, but don’t flag clomipramine as at risk of being finagled downwards, I worry you’re likely to understate clomipramine’s case.
I make a big deal of this because about a dozen of the twenty clomipramine studies included in the analysis were very obviously pharma companies using clomipramine as the comparison for their own drug that they wanted to make look good; I suspect some of the non-obvious ones were too. If all of these are marked as “no risk of bias against clomipramine”, we’re going to have clomipramine come out looking pretty bad.
Clomipramine is old and canonical, so most of the times it gets studied are because some pharma company wants to prove their drug is at least as good as this well-known older drug. There are lots of things like this, where certain drugs tend to inspire a certain type of study. Cipriani says they adjusted for this. I hope they were able to do a good job, because this is a big deal and really hard to factor out entirely.
This is my excuse for why I’m not rushing to prescribe drugs in the exact order Cipriani found. It’s a good study and will definitely influence my decisions. But it’s got enough issues that I feel justified in taking my priors into account too.
III.
Speaking of which, here’s another set of antidepressant rankings:
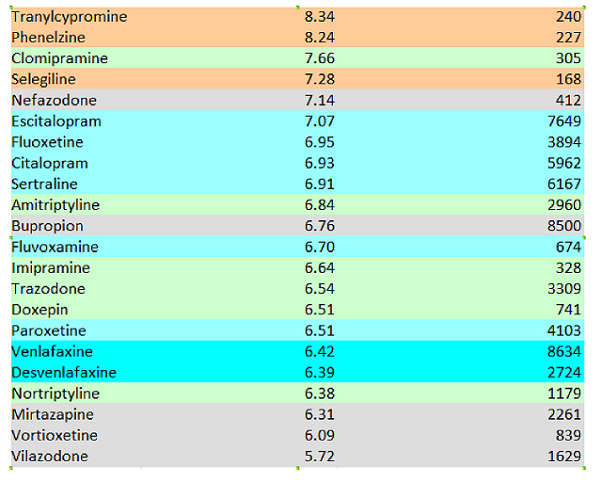 This is from Alexander et al 2017, which started life as this blog post but which with help from some friends I managed to get published by a journal. We looked at some different antidepressants than Cipriani did, but there are enough of the same ones that we can compare results.
This is from Alexander et al 2017, which started life as this blog post but which with help from some friends I managed to get published by a journal. We looked at some different antidepressants than Cipriani did, but there are enough of the same ones that we can compare results.
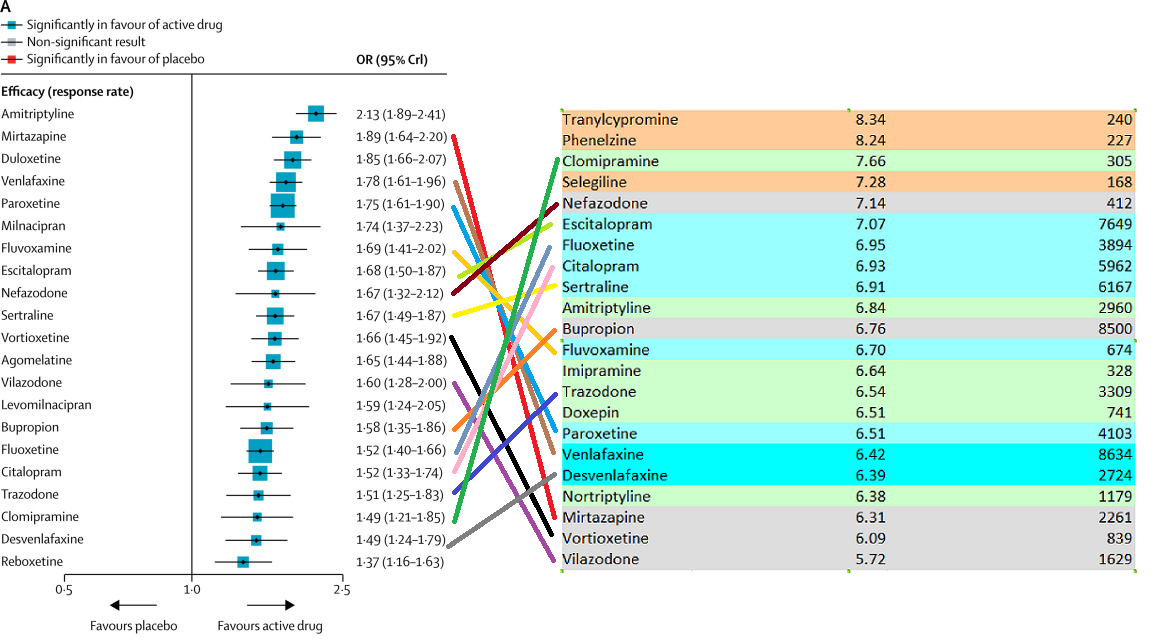 Everything is totally different. I haven’t checked formally, but the correlation between those two lists looks like about zero. We find mirtazapine and venlafaxine to be unusually bad, and amitriptyline to be only somewhere around the middle.
Everything is totally different. I haven’t checked formally, but the correlation between those two lists looks like about zero. We find mirtazapine and venlafaxine to be unusually bad, and amitriptyline to be only somewhere around the middle.
I don’t claim anywhere near the sophistication or brilliance or level of work that Cipriani et al put in. But my list – I will argue – makes sense. Drugs with near-identical chemical structure – like venlafaxine and desvenlafaxine, or citalopram and escitalopram – are ranked similarly. Drugs with similar mechanisms of action are in the same place. We match pieces of psychiatric conventional wisdom like “Paroxetine is the worst SSRI”.
Part of the disagreement may be related to all the antidepressants being very close together on both lists. On Cipriani’s, the difference between the 25th vs. 75th percentile is OR 1.75 vs. OR 1.52. On mine, it’s a rating of 7.14 vs. 6.52. Aside from a few outliers, there’s not a lot of light between any of the antidepressants here, which makes it likely that different methodologies will come up with very different orders. And the few outliers that each of us did identify as truly distinct often didn’t make it into the other’s study – Cipriani doesn’t have MAOIs and I don’t have reboxetine. But this isn’t a good enough excuse. One of my top performers, clomipramine, is near the bottom for Cipriani. One of my bottom performers, mirtazapine, is near his top. I have to admit that these just don’t match.
And a big part of the disagreement has to be that we’re not doing the same things Cipriani did – we’re looking at a measure that combines efficacy and acceptability, whereas Cipriani looked at each separately. This could explain why my data penalizes some side-effect-heavy drugs like mirtazapine and amitriptyline. But again, this isn’t a good enough excuse. Why doesn’t my list penalize other side-effect-heavy meds like clomipramine?
In the end, these are two very different lists that can’t be easily reconciled. If you have any sense, trust a major international study before you trust me playing around with online drug ratings. But also be aware of the study’s flaws and why you might want to retain a bit of uncertainty.